Infix opretors

Infix functions (operators) can help clean up your data model and maintain preferences for an order of operation
Most of the functions in R programming are written with the arguments set within a parenthesis. But once in a while, the order of arguments needs a different format to keep an intended order of expression. Infix operators (also called “infix functions”) provide that different format, a syntax for pairing arguments while providing a mathematical order of expressions recognized by the program.
Infix operators are not a usual choice — there are many ways to create a function, like the new operator for R programming which I explain in this post. Yet data science and programmers can use infix functions to expand their options. It can be a great way to simplify formulas applied to arrays and matrices — a need that comes up frequently with data placed in data frames, data tables, and other classes of objects.
What Is An Infix?
So let’s get the basics out of the way. What is an infix operator? What does it do?
An infix operator is a function that applies a calculation to arguments on either side of the function operand. In R the operand involves a function name surrounded by percentage signs.
How Infix Operators Works
An infix is one of three operation protocols created to address mathematics within programming. Developers need to ensure that the mathematical order of arguments in a calculation is aligned with an order of precedence within the syntax of a given programming language. The alignment ensures that a mathematical or logical sequence occurs as the developer had expected. Developers often create mathematic and functional expressions in a line of code, ranging from simple expressions, like assigning one argument to a constant, or a compound of expressions, like applying formulas to assigned variables. Understanding the order of precedence ensures that arguments are called as needed within a program.
If you are not sure about how to envision this, just think about how math operators work. People are taught the order of operation — parenthesis before exponents, multiplication and division before addition and subtraction, and so forth.
But when mathematical operators are used in a program, you often run into moments when you need to make sure the order occurs with respect to the objects and expressions that are being called. With arrays and vectors, that can get complicated.
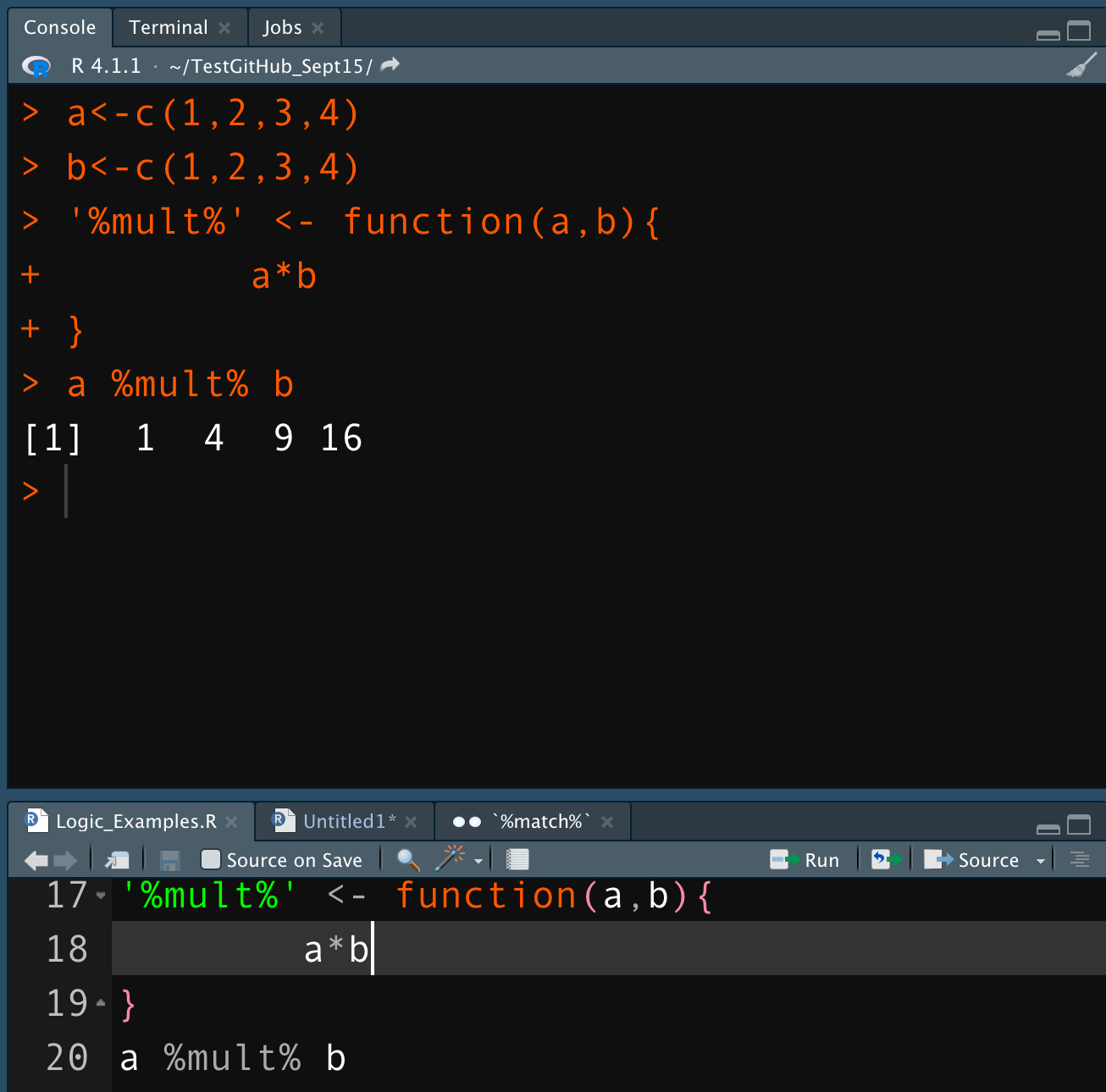
For example, you can apply math to a range of numbers in R, but you also alter the object in some ways as well. In the example, you have a range of numbers called by 1:4. You can multiply the range and get a vector with an expected number of data.
But R returns different results when raise to an exponential power. The returned vector is longer rather than the original 1:4 range. If you imagine that range representing a column of data from a table, you can imagine the problem. You want to apply a mathematical operation without creating additional data incidentally.
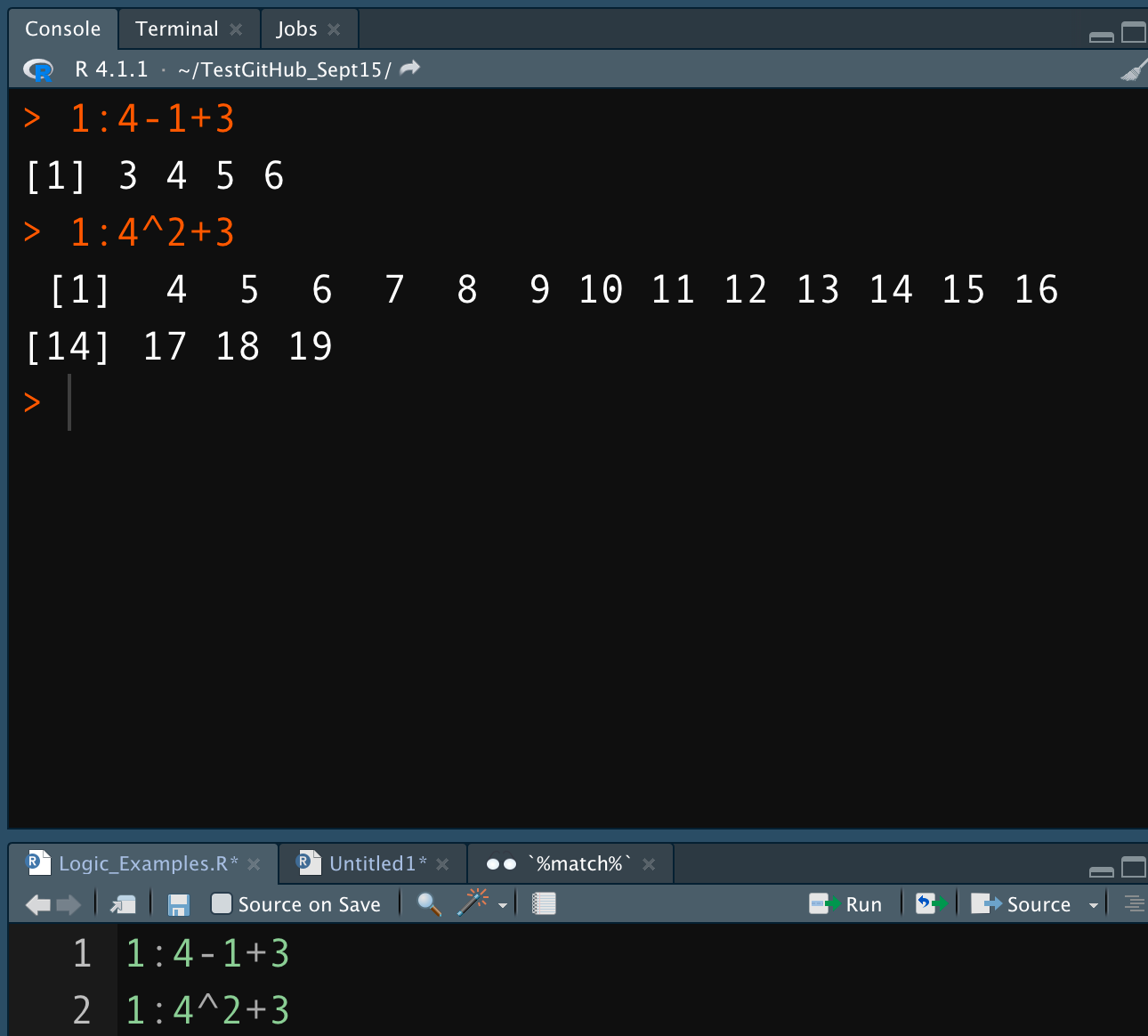
Now, I will admit a small conceit — in the exponential example, placing parenthesis around the range can eliminate the long vector problem.

But the important takeaway is that there will be instances where you will want to clarify a formula more complex than an exponential power or call data with a variable, such as calling table columns in R with the $ sign. That’s where evaluations (and infixes) can help.
What is a Lazy Evaluation
A convention for programming languages had to be developed to allow calculations, but not alter elements in an object because of the order of mathematics applied. That convention is called an evaluation strategy — in this case, a lazy evaluation. A lazy evaluation means the expressions in the line of code are not evaluated until a symbol tells the language to do so. It is a way of setting an order convention for the expressions.
Plus, a lazy evaluation can make the syntax more readable to programmers and easier overall to debug. Evaluation methods are taught as part of the language. Understanding how evaluation operates within a language encourages syntax choices that are considered readable and, consequently, easier to catch minor errors (or form questions on how to manage syntax better).
Thus came the introduction of prefix, infix, and postfix operators in programming. These operators are named according to where the arguments appear. A prefix operator (called a Polish notation) means that you have the function called with the arguments following within brackets or parentheses. An infix operator allows a function to be called between two given arguments. A postfix operator just places the arguments prior to the function operation.
How Infix Operators Are Used in R Programming
Most R Programming functions are written with a prefix operator. In many cases, the functions include a large number of arguments and also have parameters that programmers can set to certain arguments. Thus a prefix syntax is a standard operator convention in R Programming.
Yet a few dedicated infix operators are included in R. These are mainly meant to address mathematic operations and objects involving matrices. The built-in infix functions consist of the following:
· %% is used to call a Modulus, the remainder of two numbers in division
· %/% is used to call an integer
· %o% is used for Outer product
· %*% is used for Matrix multiplication, returning a Matrix product.
· %x% is the Knonecker Product function. According to Wikipedia, a Knonecker product is an operation on two matrices of arbitrary size resulting in a block matrix.
· %in% is a matching operator
In addition, programmers can also build an infix operator, creating the underlying function and other R syntax such as loops and if-else statements. To do so, you create a function the same way as you would for any R programming function. You assign a function to your infix, with percentage symbols and quotation marks surrounding your infix name. The infix operator is then called in the program when needed, only using the % and function name.
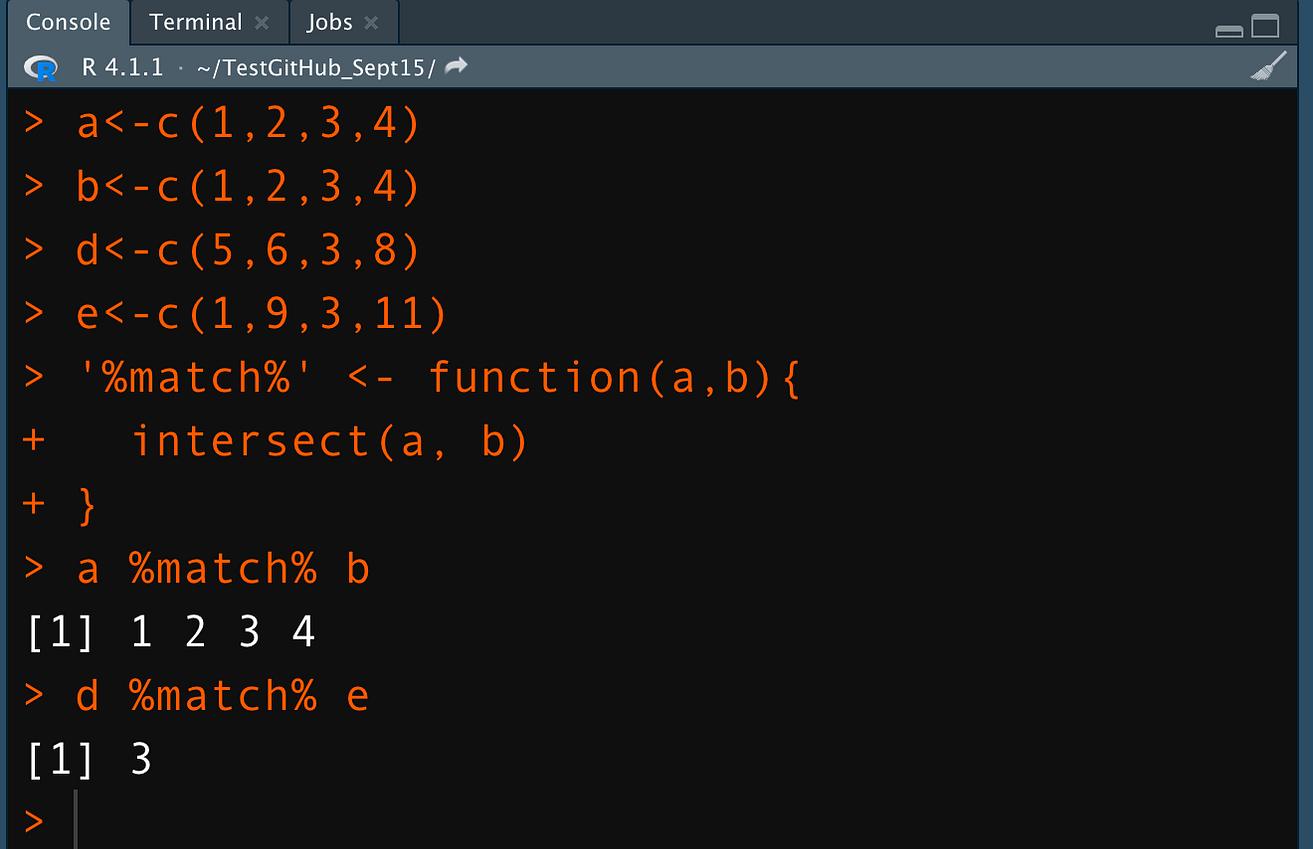
In the example below, I made a simple infix operator for matching the data in a vector. The infix %match% is called between vectors a and b and vectors d and e. It returns what data matches between two vectors. For a and b, all four data — numbers 1,2,3,and 4
are a match. For d and e, only 3 is a match among the 4 data elements.

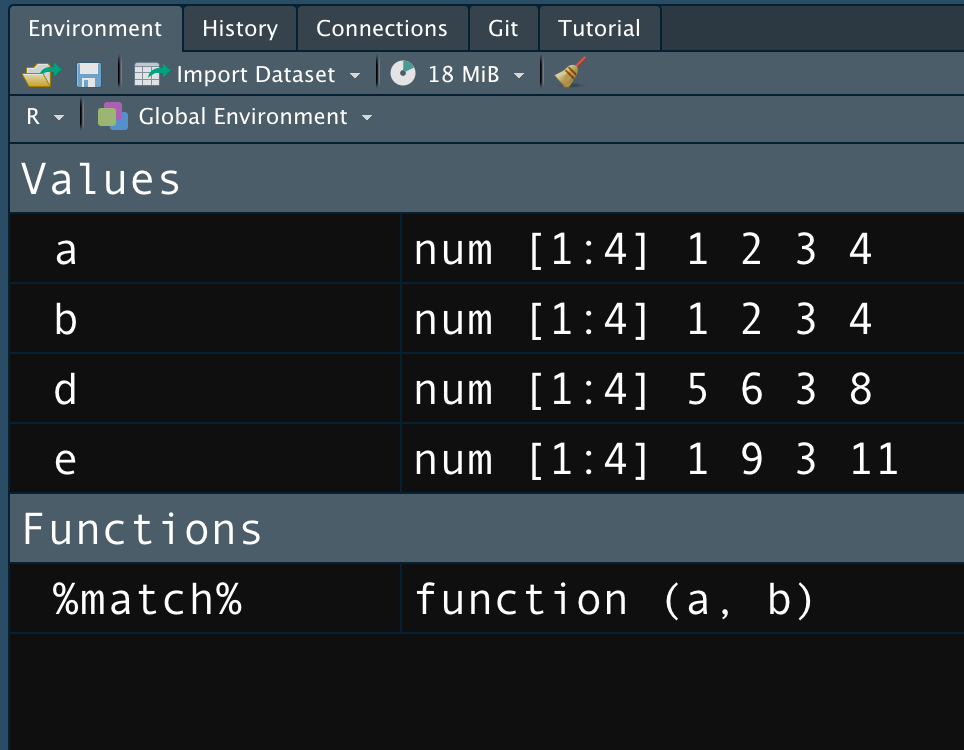
When the program runs, the operator will also be listed in the environment pane in RStudio. It will be listed as a function. If you click on the text icon on the right, the operator appears as a separate tab in the Source pane. This allows you to debug and refine the operator as needed. This is not necessary for developing an infix operator, but it can be a handy feature to use in some instances.
Overall, infix operators can help expand your options for expressions that require specific mathematical instruction while fitting within the conventions of R programming.
Earlier today we were spelunking through the add_tally() function from {dplyr} and came across this wonderful line of code:
mutate(x, `:=`(!!name, !!n))That’s an example of using prefix notation for something that we would normally write with infix notation. Let’s compare the two:
infix notation
mutate(x, !!name := !!n)prefix notation
mutate(x, `:=`(!!name, !!n))


Comments
Post a Comment